[WIP] 视频生成模型能成为世界模型基座吗
效率是直接矛盾,但不是根本矛盾。
生成式AI的格局相比一年前我调研的时候已经大不相同:DiT的架构趋于收敛;NanoBanana、Seedance等闭源模型也实现了极好的生成效果;开源模型不再军备竞赛式更新。但是问题仍然存在:AIGC应该如何变现?如何在实际生产中产生革命性的作用?就像LLM发展为Agent一样,通过提供工具调用能力,掀起一波token消费的浪潮。目前在aigc中,我们没有看见这一点反而是Sora2停摆,Seedance2降速,无不反映着视频生成面临的尴尬处境:很fancy,但没用。
那么视频生成模型(VM)的Agent形态是什么呢?世界模型(WM)。今天我们来阅读一篇综述:Video Generation Models as World Models: Efficient Paradigms, Architectures and Algorithms,来自香港大学。
为什么说视频模型拥有作为“世界模拟器”的能力呢?世界模型的定义:一种环境动态的表征模型,可以通过历史的上下文+当前行为(actions)预测未来的状态。对于视频生成模型来说,生成过程就是对物理世界的模拟过程——它需要考虑到自然环境的重力、碰撞和各种因果关系才能够生成足够“真实”的视频。
因此,视频生成中常用的video frames + prompt的生成方式,也是世界模型中历史上下文+行为的一种输入模式。考虑到现在的模型生成质量足够优秀,我们可以大胆猜测:经过大量视频片段的训练,模型习得了真实世界中足够的物理常识和经验。
综述中说,视频模型作为world simulator有这些好处:
- 物理智能:经过大规模训练的模型能够学习到传统分析所无法驾驭的复杂的交互作用,例如智能体与环境的交互或流体动力学。
- 潜空间分析:视频模型通常在压缩过的潜空间(Latents)中运行,这使得世界模拟能够以比高分辨率像素渲染更低的计算成本实现。
- 统一推理:通过将视频生成视为世界模型,相同的架构可以应用于从媒体制作到自动驾驶和机器人操作等各种领域,在这些领域中,模型充当通用的决策模拟器。
这些并不算是非常promising的好处,只是我们暂时没有更好的替代罢了。
限制VM作为高效的世界模拟器的,主要是效率问题。可用的世界模型要求实时的响应速度(具身、智能驾驶),这是当前VM所不具备的,扩散的迭代去噪模式导致的高计算和高延迟,自回归模式则引入巨大KV Cache开销,无不阻碍着VM向使用WM转化。
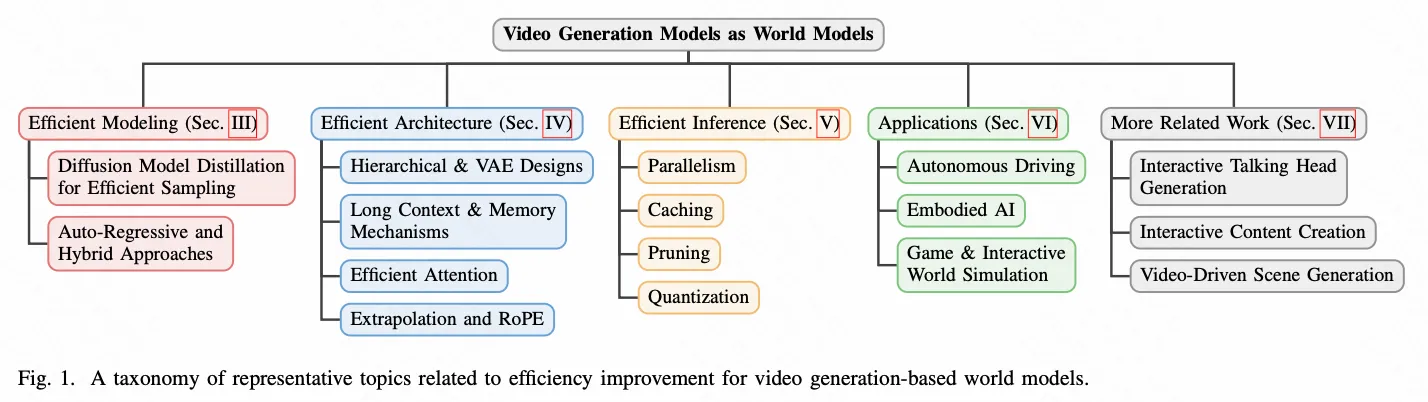
这篇综述关注就是如何从算法、架构、推理优化的角度去提升VM的效率,同时给出VM向WM转化的应用和相关工作。
对于不了解VM的读者,我尝试简洁地描述本文关注的workload,进行一次阅读所必须的background同步。
视频生成模型的 workload 特征如下:视频经过时空 tokenize 得到 latent 序列,与条件信息一起送入 DiT(Diffusion Transformer)。DiT 是核心 backbone,其计算瓶颈在 full attention,全过程计算密集,长序列时 self-attention 占总计算时间 80% 以上。生成(Inference)是迭代去噪过程,每一步 DiT 输出经采样后需重新送入模型,所有 token 均被更新,因此无法像 LLM 解码阶段那样利用 KV cache 加速。
如果你了解llm,那么视频生成过程从负载上等同于一个长序列的多次prefill过程,你也就能理解为什么它那么慢。
Efficient Modeling
这一章节主要介绍从采样算法的角度加速生成过程。
蒸馏与采样优化
传统模式是迭代式全序列去噪,每个采样点从起点分布到最终生成目标分布。蒸馏等算法优化致力于减少生成所需要的步数,核心是轨迹优化和步数减少——将轨迹拉直,将步子跨大。
-
Consistency distillation:一致蒸馏
Student去用更少的采样点拟合teacher的轨迹。希望直观地通过对大量点到点映射关系的学习掌握轨迹的规律。其损失函数往往建模为: \(\mathcal{L}(\theta)=\mathbb{E}\left[\left\|教师输出(t)-学生输出(s)\right\|_2^2\right], \quad s<t,\)
-
Adversarial distillation:对抗蒸馏。尝试学习分布层面的特征,而不是逐点回归,从数学意义上会更加接近本质一点。其损失函数建模为分布间的差异指标,比如KL散度或者像GAN一样可以被学习的隐式差异: \(\min _\theta D\left(p_S(\cdot \mid c) \| p_T(\cdot \mid c)\right)\) 虽然蒸馏方法能够大幅度降低计算成本(50步到6步,甚至1步生成)步数的减少意味着轨迹调整的机会减少,模型的容错能力降低,反映为生成质量的下降和多样性的下降。而且,这依赖于model-specific的额外训练,并不足以令人满意。
自回归和混合方案
传统基于扩散的VM还有一个关键局限:生成的序列长是固定的,无法基于已有内容持续续写,这也与实时世界模型的要求不相符合。研究者在VM中引入自回归AR机制,就是为了解决这个问题。
相关工作有VideoGPT,VideoPoet,Loong,iVideoGPT等。其中的关键挑战是序列可扩展性和生成保真度的权衡:从目前的生成效果看,高质量的视频输出高度依赖于full attention的全局视野和密集计算,自回归的模式同时削弱了这两点,因此生成效果往往差强人意。
AR能够在语言模型中如鱼得水,我认为有赖于语言(一维)本身是人类发明的高度信息压缩的产物,容易分割,意义明确;但是对于图像(二维)甚至视频(三维),再好的Encoder也没办法用有限的token完整而准确地表达其内蕴的信息,因此只能寄希望于full attention的全局视野和密集计算,以及一次又一次的迭代和去噪修正。只能说视觉生成的算法和架构还有很大的进步空间。
混合生成:AR+Diffusion,帧维度自回归,图维度扩散。
因果流式生成:效果不够好?