记第一次正式求职面试
我们需要业界的负载和战场。
考虑到对方是多模态的推理Infra部门,我需要补充一些基本的LLM侧推理和算子基本知识。奋斗两小时能把面试官糊弄过去吗?
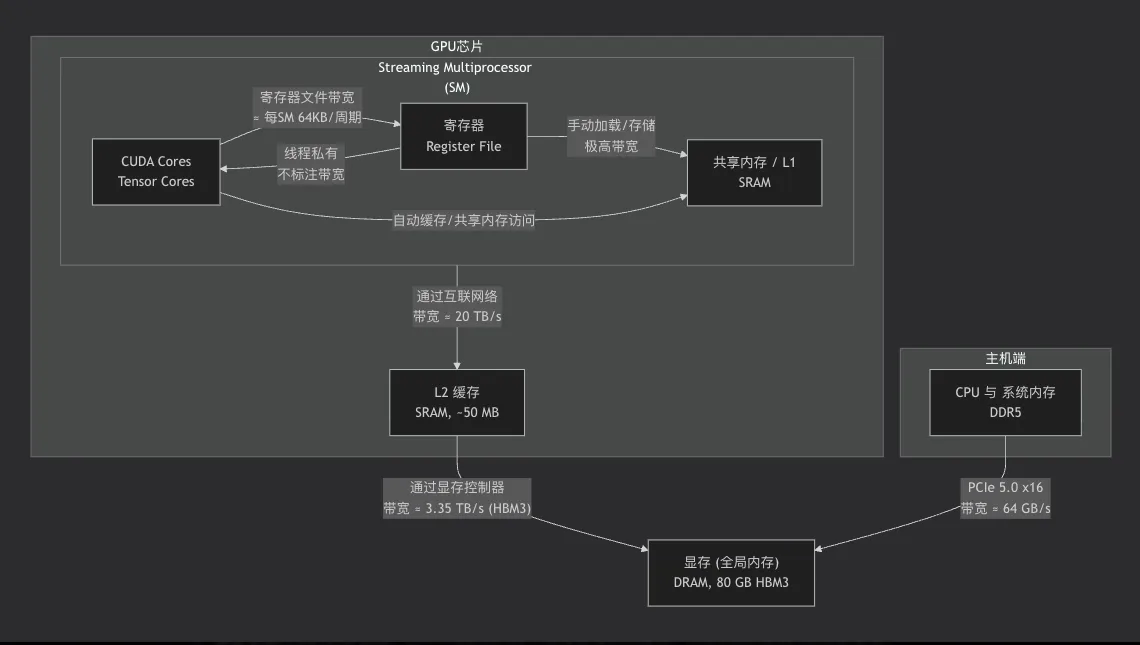
GPU Architecture
GPU 的访存系统采用层次化设计,自顶向下容量递增、延迟递增、带宽递减,并与计算单元紧密绑定:
| 存储层次 | 物理位置 | 作用域 | 典型容量 (以 A100 为例) | 访问延迟 (周期) | 聚合带宽 (TB/s 级) |
|---|---|---|---|---|---|
| 寄存器 (Register File) | 每个 SM 内部 | 线程私有 | 每 SM 约 64 KB (256 KB 总寄存器文件) | 1 | 极高 (每周期每线程可访问) |
| 共享内存 / L1 缓存 | 每个 SM 内部 | 线程块共享 / 自动缓存 | 每 SM 共 192 KB (可配 16+16 等) | ~25 | ~40 (全芯片聚合) |
| L2 缓存 | 芯片全局 | 所有 SM 共享 | 40 MB | ~200 | ~20 |
| 显存 (HBM/GDDR) | 片外 DRAM 颗粒 | 全局内存 | 80 GB (HBM3) | ~290 | 3.35 (HBM3) |
注:共享内存与 L1 在物理上共用同一块 SRAM,可通过配置划分比例。
计算结构与访存层次的绑定
- 寄存器 → 线程 (Thread):每个线程拥有私有寄存器,存放临时变量与中间结果,延迟最低。
- 共享内存 → 线程块 (Thread Block):同一线程块内的线程可通过共享内存高效交换数据,需显式同步 (
__syncthreads)。 - L2 缓存 / 显存 → 网格 (Grid):所有线程均可访问,L2 自动缓存显存数据,对程序员透明;显存是最终大容量存储。
这种绑定关系决定了 GPU 编程的核心优化原则:
- 数据就近放置:将频繁访问的数据尽量放在寄存器或共享内存中。
- 合并访问:当必须访问显存时,确保同一 Warp 的线程访问连续地址,以充分利用 HBM 的突发传输带宽。
- 利用计算隐藏访存延迟:通过高占用率,在等待显存数据时切换至其他线程束。
补充说明
- 寄存器数量限制:每个 SM 的寄存器总数固定,若线程块内线程过多或单个线程使用寄存器过多,会降低占用率,可能迫使数据溢出到本地内存(实际存于显存,延迟激增)。
- 共享内存 bank conflict:共享内存被分为多个 bank,若同一 Warp 内多个线程访问同一 bank 的不同地址,会导致串行化,需避免。
- L2 缓存与显存的带宽关系:L2 带宽约为显存的 6 倍,但容量小;显存带宽虽远高于 PCIe(如 H100 显存 3.35 TB/s vs PCIe 5.0 64 GB/s),仍是片上缓存的瓶颈。
以上层次设计体现了 GPU “吞吐优先、容忍延迟” 的架构哲学:用大量线程掩盖访存停顿,用分层存储平衡速度与容量。
Bank Conflict
Bank Conflict 是指当同一个 Warp(32个线程)中的多个线程同时访问共享内存(Shared Memory)中同一个 Bank 的不同地址时,硬件被迫将这些访问请求串行化(一次只处理一个),从而显著增加访问延迟的现象。共享内存的 Bank 数量通常为 32 个,每个 Bank 每周期可以响应一个地址的访问;若线程访问的地址均匀分布在不同的 Bank 上(无冲突),则一个周期即可完成;反之,一旦多个线程命中同一 Bank 的不同地址,就会产生冲突,导致实际带宽下降,极端情况下最坏性能只有无冲突时的 1/32。
Flash Attention 基本原理
如何计算FLOPs
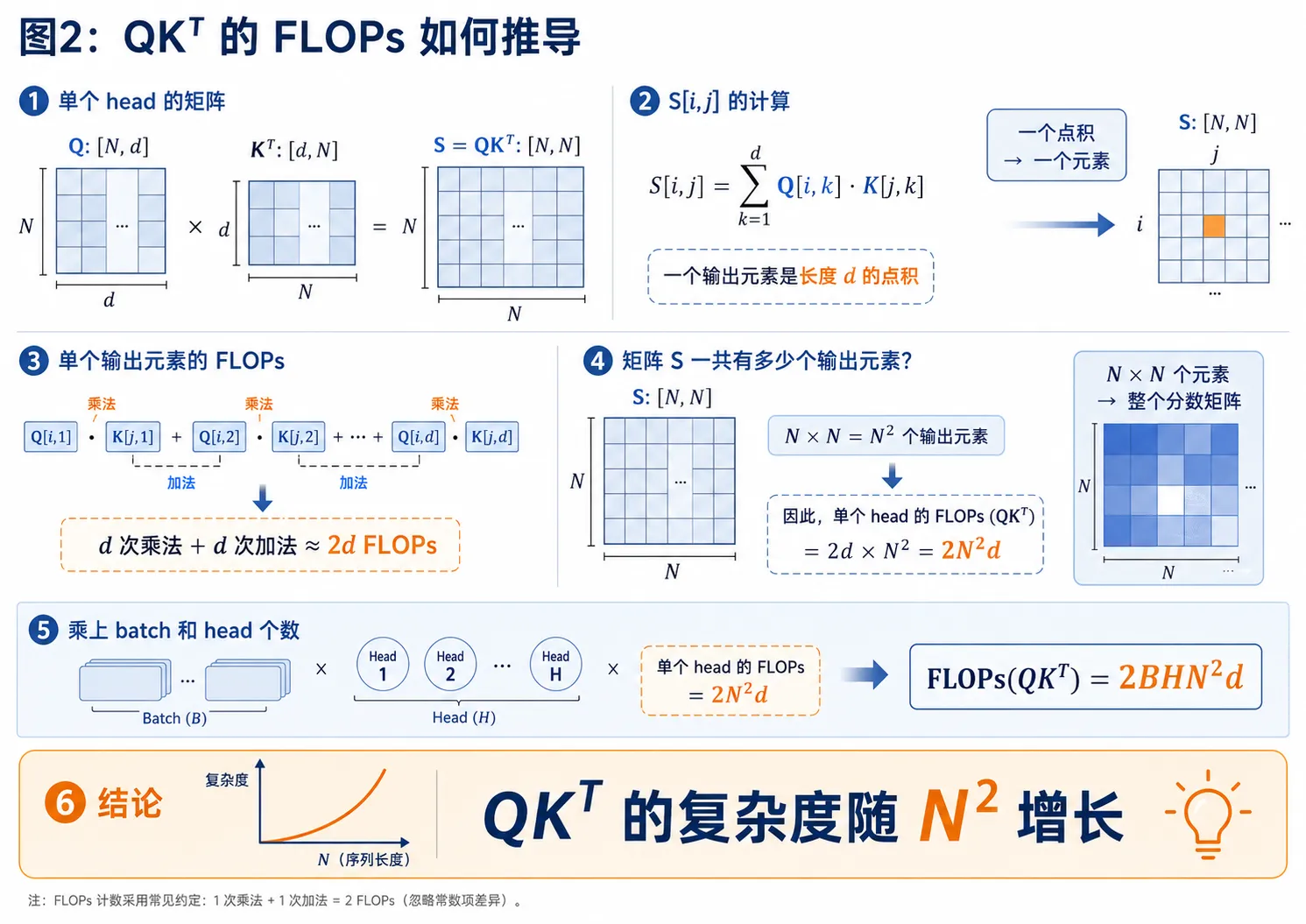
注意d维向量的内积FLOPs是2d,乘法和加法各自均匀计算一遍。一个输出元素对应2d的计算量,Softmax矩阵是$N^2$个输出元素。Head和Batch都是独立的维度。
Roofline Model
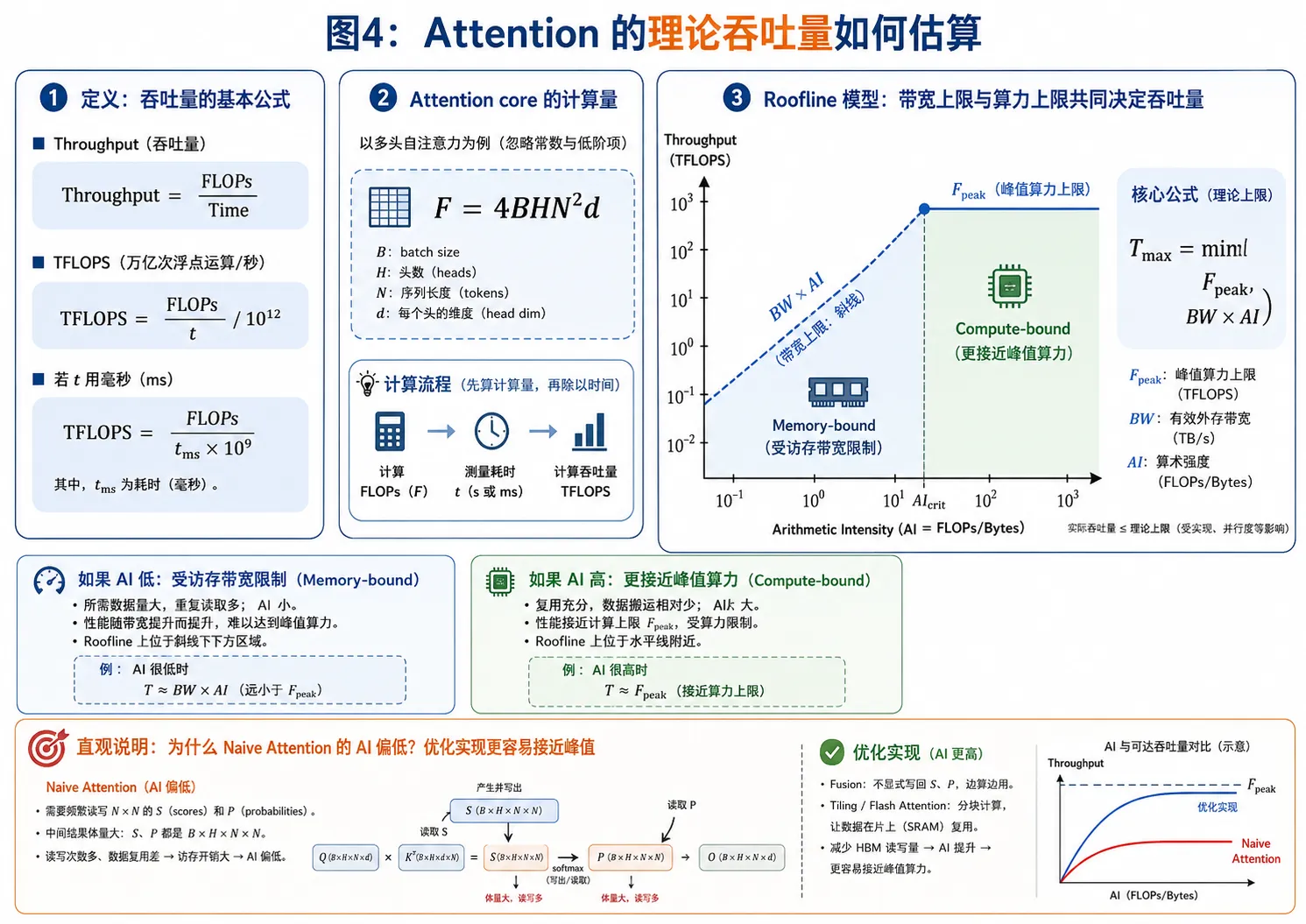
纵轴是Throughput(FLOPs/time),横轴是计算强度。计算强度不足的状态下,受到访存限制,无法将吞吐量打满。
Roofline model能很好地解释LLM的Prefill和Decode阶段吞吐量差异的原因。由于KV Cache的存在,Decode阶段的计算强度变为$2BhNd$,一般而言受到访存限制。
Flash Attention 核心技术
在Naive Attention中,访存瓶颈来源于S矩阵无法被完整储存在SRAM中,因此需要写出到DRAM中,从S到P会引入大量的DRAM读写开销。工作流:读取QK并计算,S写回HBM,从HBM读取S计算softmax得到P,P写回HBM,从HBM读取P,计算PV得到O,将O写回HBM(Global Memory)。
Flash Attention 提出的三大核心技术——分块 (Tiling)、在线 Softmax (Online Softmax) 与 算子融合 (Kernel Fusion),精准地解决了搬运瓶颈,实现了更快的速度。工作流:从HBM读取QKV的tile,在Shmem/L1完成QK+softmax+PV,将累积的O tile写回HBM。
vLLM
Paged Attention
Motivation:传统的推理引擎对每个请求预留连续内存存放KV Cache。这里有两个问题:1. 预留 2. 连续。
预留意味着要基于最大序列长度开辟空间。连续则造成了不可避免的内存碎片化。当没有足够的连续空间时,请求就会被阻塞。
vLLM发现,服务场景下,显存的利用率极低,限制了服务的并发能力。
借鉴传统页表机制,vLLM将KV Cache切分为固定大小的“块”,在将逻辑连续的内存通过块表映射到不连续的物理显存上。物理块动态按需分配,相同前缀的请求还可以共享KV Block。
Continuous Batching
传统服务往往采用静态批处理(static batching),等待足够的请求,batch起来后同时进入prefill和decode阶段。需要等待所有请求都完成才能返回。此时长尾分布会严重限制服务的性能。
Orca(osdi22)提出了动态批处理,被vLLM作为核心调度策略使用。系统维护一个全局的待处理请求队列,以及一个活跃请求池。
每生成一个 token 后,检查每个活跃请求:
- 如果该请求已经生成了
EOS或达到最大长度,则将其从活跃池中移除,释放其 KV Cache(利用 PagedAttention 的物理块回收)。 -
如果该请求仍在进行中,则继续保留。
- 同时,检查是否有新的请求到达,如果有且 GPU 还有空闲计算能力(通常以剩余的 KV Cache 块数量或最大批次大小限制为准),则将新请求立即加入活跃池,并在下一轮迭代中开始处理。
可选策略-抢占或交换:当显存不足时,可以将某些请求的 KV Cache 暂时换出到 CPU 内存,稍后再换回。vLLM 也支持这种“交换调度”。
Chunked Prefill
传统LLM推理中,Prefill计算密集,耗时较长。一个长序列的Prefill会直接占用所有GPU资源,并阻塞所有Decode的请求。
思路:将长序列prefill切块,在prefill的块间加入decode调度。提高了调度的灵活性。
PD分离
Continuous Batching和Chunked Prefill实现了 推理过程的时分复用,PD分离则是实现了阶段的空间隔离。可以对TTFT和ITL做独立的调优,甚至做异构硬件的适配。
PD分离的核心开销在于KV Cache的传输。在PD分离的情况下,一个请求完整的生命周期为:请求到达路由器,路由到P节点(生产者),生成完整的KV Cache,再通过高速网络传递给D节点(消费者)。
SGLang
RadixAttention
Motivation:一个任务往往包含多次连续的生成调用。传统的推理引擎在处理完一次请求后,会将对应的KV缓存直接丢弃。这意味着,当一个新请求与历史请求共享相同的系统提示词、少样本示例或多轮对话历史时,相同的前缀会被反复计算,造成巨大的计算和显存浪费。
通过RadixTree-将KV Cache组织为树状结构,将请求的公共前缀(系统prompt)高效共享,消除重复的计算。vLLM基于paged attention对Block进行前缀匹配,SGLang则是最长前缀匹配算法,最大化缓存命中率。HiCache构造GPU->CPU->分布式缓存三级缓存机制。
FlashInfer
Motivation:注意力计算本身就因Prefill和Decode阶段有着巨大的计算访存比差异,更复杂的任务如投机采样(Speculative Decoding)或为提升缓存效率的分页(PagedAttention),会导致更复杂的稀疏存储格式。单一的注意力内核无法在这些差异巨大的场景下都保持高效。
FlashInfer构建了一套高度灵活和高效的注意力引擎,主要贡献如下:
- 统一抽象:核心是块稀疏格式 (Block-Sparse Format, BSR)。它将所有稀疏模式统一表达为固定大小的块,极大简化了实现并让格式适配GPU架构,通常能达到同类问题下密集计算90%的带宽效率。
- 平衡效率与灵活性:引擎提供高度灵活的编程接口和可定制的注意力模板,并通过JIT编译实时生成最优的GPU代码,无需人工维护大量繁琐的模板。
- 大规模调度:包含动态负载均衡调度框架,能有效应对不同请求的计算需求差异,同时兼顾与CUDA Graph的兼容性,保持静态配置的高效。
面试记录
一面很轻松地过了,没有手撕代码,面试官问了一些关于我工作的基本问题,感觉他没我懂,这也理所应当。两天后就是二面,也是终面。
这次仍然没有手撕代码,也没有问任何我准备了的领域,仍然是自我介绍+工作介绍,但这次后劲可就太足了,40分钟面试让我冷汗直流。这位infra的负责人语速飞快,6页ppt飞速扫了几眼。
-
ModalPlex:直接给出了解决方案,嘲讽我们把问题复杂化了。并且这个解决方案确实是最优的。
-
DiTango:第一个关于跨机扩展的问题我勉强接住了,一看到我用了cache去优化又立马开始嘲讽:工业场景中的模型一定会经过蒸馏,这时cache方法就直接废了——确实如此。我只好狡辩我接触的负载里面,cache仍然可用,但我原本的高傲感基本没了。
-
Jano/CuBic:我已经不好意思说了,仍然是cache的方法。好歹是个算法优化,总有比你infra工程师懂的地方了吧。结果他直接开始问算法问题,又把我纸老虎给捅破了——我只会一点点,还不够深入。
总之,我引以为傲的几篇工作在业界大佬眼里一下子变成了几个小玩具。总算明白什么叫做“拷打”了。
后面,他问我还有什么问题,我大脑一片空白,只想再确认自己工作的价值。他也不置可否。
最后,我试探性地问了一下他的身份,因为假如只是个小mentor,我真得抑郁了。
还好,是总负责人。
我只能表达对他的敬意,如果能在他指导下科研工作,该是多么美好的事情。不需要事无巨细地解释,每句话一针见血。
希望有机会见到他吧,一定找机会再请教。
2026年3月24日,据36氪,接近腾讯混元团队的知情人士透露,原字节Seed视觉AI平台团队负责人肖学锋,Infra团队张弛于近期低调入职腾讯,负责大模型Infra相关工作,向腾讯首席AI科学家姚顺雨汇报。2025年年底,腾讯升级大模型研发架构,新成立AI Infra部,由姚顺雨担任部门负责人。据了解,肖学锋入职后,直接担任该部门的助理负责人,协助姚顺雨负责该部门管理工作。同时,该部门内的训练Infra组负责人黄启,也来自字节seed团队。