用torch.compile和CUDA Graph拉满Diffusion推理性能
快来使用ChituDiffusion!
这是一篇”边做边学”的工程实录。我们在THU PACMAN组自研的生成加速框架 ChituDiffusion 上,尝试对经典文生图模型 Flux.1-dev 做优化,探索
torch.compile与 CUDA Graph的原理和实际应用场景。拜伟大的AI所赐,全文每个数字都可一键复现,命令、配置、trace、代码链接都附在文末归档目录里,整套流程走下来,你对 Diffusion 推理的数据特征和加速思路,都一定会有更深的理解。
先看结果——同一条 prompt、同一个 seed,经过优化后,端到端提速 9.74×,而出图肉眼无差,如果换上更强的attention后端,性能还能进一步拉高,接近实时:

Flux.1-dev,1024²,50 步。这并不是一个计算全在 Full Attention 上的长序列负载,真正跑过的人都知道,这个加速来得并不容易。
0. 扩散模型的”无损加速”格外珍贵
我们知道,LLM推理有两个阶段:prefill 阶段计算密集、decode 阶段访存/发射密集(每次只算一个 token, GPU 经常在等 CPU 喂活)。所以 LLM 上 CUDA Graph、连续批处理这类”减少发射开销”的技术收益巨大。
但扩散模型(DiT)不一样:它是迭代去噪,同一个网络被反复调用几十步,每一步都要对整张 latent 做完整前向——全程计算密集,GPU 本来就接近打满。这带来两个后果:
- 朴素的调度和”减少发射开销”未必有用(GPU 没空等);
- 正因为 GPU 已经很忙,任何不增加误差的提速都极其宝贵。
因此当前主流的扩散加速——稀疏注意力、量化、特征缓存复用——几乎都要拿画质换速度。本文想回答 一个问题:在不动数值语义、不掉画质的前提下,还能压出多少性能? 答案是:单卡 1.2×、 8 卡 ring 5.06×,叠上近无损的 FlexCache 缓存后端到端 9.74×。
ChituDiffusion是我们的试验田:这是一套把Diffusion推理过程分阶段抽象,并把”模型 / 并行方式 / 注意力后端 / 缓存策略”等主流加速策略全做成可插拔配置的框架。换模型、换后端、加优化开关,都只是改几行 YAML。框架同时配置了ChituBench,灵活的计时器和全面的质量指标,让我们能时刻保持延迟-质量的全局视野。
这套”快速受控实验”的能力,让本次实验能在多模型多配置间灵活切换和验证。
1. 原理:torch.compile 与 CUDA Graph
这两个名字往往被混为一谈,其实它们针对完全不同的两个层面,只是他们叠加起来会有更好的效果。
| torch.compile | CUDA Graph | |
|---|---|---|
| 来历 | PyTorch 2.0(2023)引入的 JIT 编译栈 | CUDA 10(2018)引入的图执行 API |
| 是什么 | TorchDynamo 抓图 → 自动生成融合 kernel | 运行时把一串 kernel 发射录制成图,一次回放 |
| 优化对象 | GPU 要干的活本身(kernel 更少更胖、访存更省) | CPU 派发这些活的开销(每个 kernel 的 launch / 调度) |
| 改变计算吗 | 改变(融合、重排、选更优 kernel 模板) | 不改变(同样的 kernel、同样数量、同样结果) |
| 收益场景 | 访存受限、Python dispatch 多 | launch-bound(kernel 又多又小、GPU 没喂饱) |
1.1 torch.compile:把”碎 kernel”压成”大 kernel”
PyTorch 2.x 编译栈分两层:TorchDynamo 在 Python 字节码层抓计算图(遇到它”看不懂”的动态控制流 就 graph break 把图切段),Inductor 把每段图降级、生成融合后的 Triton/C++ kernel。加速主要来自:
- 算子融合:把 LayerNorm、GELU、
(1+scale)*x+shift(adaLN 调制)这类逐元素/归约操作合并成 一个 kernel,大幅减少对显存(HBM)的反复读写——这些操作是访存受限的,省下的就是带宽往返。 - 省掉 Python 逐算子开销:eager 下每个算子都要过一遍 Python→C++ 的 dispatch;编译成一个大 kernel 后,这些 host 侧的派发开销一次性消失。
- autotune 选更优 kernel:Inductor 会对同一个算子实测多套实现(不同 tile / block 配置), 挑当前形状下最快的那个,而不是用一个通用默认核。
- layout 优化与常量折叠:自动调整张量内存排布以贴合 kernel 访存模式,并把推理期恒定的子表达式 (如固定的缩放系数)在编译期算好,免得每步重算。
注意:编译后运行时仍在一个个发射 kernel,只是 kernel 变少、变胖了。
1.2 CUDA Graph:把”一串发射”录下来一次回放
CUDA Graph 把”一长串 kernel 发射 + 它们的依赖”录制成一个 graph,之后一次 cudaGraphLaunch
就回放整串操作。它只解决一件事:消除每个 kernel 的 CPU 端发射开销和 CPU-GPU 调度空隙。
单次发射约几微秒,当一次前向有成百上千个小 kernel、或并行场景里夹着大量通信调度时,累加起来很可观。
它不融合 kernel、不减少计算量。硬约束也很明确:形状固定、显存地址固定(用静态 buffer,
每步把新数据 copy_ 进去)、捕获区内不能有依赖 CPU 的控制流、不能 .item() 同步、不能动态分配显存。
1.3 能不能加速”多步 + 多 block”的diffusion
我们来看 torch.compile 和 CUDA Graph 的应用场景:
- torch.compile: 一大堆碎而小的torch kernel
- CUDA Graph:GPU Kernel之间存在空隙,那是CPU的调度和launch开销
再看diffusion的经典负载特征:
- 多步:同一张图被回放几十次,capture 一次、replay N 次,固定开销被摊薄到几乎为零。
- 多 block:DiT 是几十个形状完全相同的 transformer block 堆叠,是 Inductor 融合的理想对象, 也是 CUDA Graph “同一段反复执行”的理想对象。
- 形状固定:去噪过程中张量形状、kernel 序列逐步不变,满足 CUDA Graph 的静态前提。
我的评价是:能用,但是有没有收益不好说。因此我们要基于trace profile的结果对症下药。下面进入实战。
2. First thing first:baseline性能分析
先用 ChituDiffusion 跑一个零优化基线(Flux.1-dev,1024×1024,flowmatch-euler,单卡 H20), 拿到稳态端到端时延和kernel时间。
为了便于调试,我们在code/block_trace_lab.py中单独 trace 一个 Flux 单流 block,形状与真实Flux1-dev 完全一致(单卡 S=4608、dim=3072、24×128、bf16)。
产物为traces/trace_{single_eager,single_compile,ring_eager,ring_compile_graph}.json.gz 。
观察下图,定位任一 block_iterNN 的 GPU kernel 行:一长串细碎的 aten elementwise / copy 小 kernel
(单 block 6 次 forward 共 312 个)夹在大 GEMM 之间。

dit_forward 稳态 ≈ 762.7 ms/次(flash 后端)。kernel 级拆解(57 个 block,序列 S=4608):
| 组成 | CUDA 时间占比 | 性质 |
|---|---|---|
| linear / addmm(GEMM) | ~55% | 计算,主导 |
| self-attention | ~22% | 计算 |
| elementwise / cast / norm | ~13% | 访存受限——可融合 |
| gap / 发射调度空隙 | 余量 | CPU 派发 |
看见的优化机会:在每个 GEMM/attention 之间,trace 里夹着一长串细碎的 cast / 调制 /
norm kernel——它们每个都要读写一遍 HBM,是典型的访存尾巴。这正是 torch.compile 发挥的地方。
3. Block-level torch.compile,单步无损提速 1.20×
3.1 为什么是 block 粒度
直接 torch.compile(model) 整模型会撞上两类编译不友好的代码:RoPE 的复数运算、顶层 forward 的
host 逻辑(从 ids 算位置编码、形状簿记)会让 Dynamo 频繁 graph break 甚至报错。重复几十次、形状固定的 transformer block 则可以较好地被完整编译和复用。所以我们把每个 block 交给 Inductor,顶层 forward 留在 eager。
美妙的是,ChituDiffusion 的模型都实现了统一的 block 列表接口,于是这段逻辑模型无关——对 Flux(transformer_blocks + single_transformer_blocks)、Wan(blocks)通用:
block_list_names = ["blocks", "transformer_blocks", "single_transformer_blocks"]
compiled = 0
for name in block_list_names:
module_list = getattr(model, name, None)
if module_list is None or not hasattr(module_list, "__setitem__"):
continue
for idx in range(len(module_list)):
module_list[idx] = torch.compile(
module_list[idx], fullgraph=False, dynamic=False, **compile_kwargs
)
compiled += 1
启用只需一个配置字段:
infer:
diffusion:
compile_mode: default # off / default / reduce-overhead / max-autotune-no-cudagraphs
3.2 免费午餐:1.20× 无损加速
关 profiler,warmup=1 触发编译,取 dit_forward 的 Min 作稳态单步
(首步含一次性编译,落在 Max 不计)。
| 模式 | 稳态单步 dit_forward | 相对 eager |
|---|---|---|
| eager | 762.7 ms | — |
| torch.compile(block) | 637.8 ms | −16.4%(1.20×) |
让我们看看trace:下图是同一个 block_iterNN 编译后的样子:碎 kernel 已被合并成几个胖 triton_*_fused_*(共 72 个,对比 eager 的 312 个)。

整条 timeline 的宏观形状其实变化不大(GEMM/attention 大 kernel 仍占主导), 真正的差别在那些细碎的小kernel全部不见了!——他们在compile 后被合并成几个胖 Triton kernel。把上面单 block lab 跑 6 次 forward 的 GPU kernel 数拉出来对比:
| eager | compile | |
|---|---|---|
| GPU kernel 总数 | 312 | 72 |
| 其中 Triton 融合 kernel | 0 | 30 |
| 典型 kernel | aten elementwise/copy 一长串 |
triton_red_fused_add_addmm_mul_native_layer_norm_split_*、triton_red_fused__scaled_dot_product_cudnn_attention_* |
成片的 mul/add/layer_norm/copy 小 kernel(每个都要读写一遍 HBM)被融成个位数的融合 kernel
——这正是那条”访存尾巴”被吃掉的过程:kernel 数 312→72,CPU 发射数同步减少。
trace 见
traces/trace_single_compile.json.gz(脚本先做 warmup 跳过一次性编译,所以打开就是 干净的 compiled region)。compile 是算子融合/重排,数值语义不变,同 seed 出图与 eager 视觉一致。
3.3 追问:“无损“的 compile 出图不是逐像素一致?
同 prompt 同 seed,eager 与 compile 出图的 PSNR 其实不是 ∞(Flux.1-dev,1024²,50 步,3 张海报均值):
| 对比 | PSNR | SSIM | LPIPS ↓ | HPSv3 |
|---|---|---|---|---|
| eager(参考) | ∞ | 1.000 | 0 | 12.93 |
| torch.compile vs eager | 33.0 dB | 0.944 | 0.012 | 12.97 |
原因不是”有损算法”,而是 compile 不保证 bit-exact:算子融合改变了浮点累加顺序(加法不满足结合律), autotune 又可能换用不同的 GEMM/Triton 实现,于是每个算子带一个末位级(~1e-6)扰动。扩散是 50 步串行 迭代,微扰被逐步放大,到解码时像素就有可测差异,但感知完全一致(LPIPS 0.012、HPSv3 持平)。文字/高频 内容处在”决策边界”时 PSNR 会更低(tech_poster 仅 21),可视觉与偏好分依旧无感。
同理:不开 compile,换张 GPU 或换个 cuBLAS 版本,两次 eager 也不会逐位一致——本质都是浮点非结合律。
损失是相对的,从compile角度,不compile的就是有损,反之亦然。所以此处的”无损”指 数值语义等价 + 感知无损,而非逐位一致。
4. 叠加 CUDA Graph —— 没有用?
torch.compile 集成了CUDA Graph: 把 compile_mode 切到 reduce-overhead,Inductor 会在编译好的子图上自动再套一层 CUDA Graph。
然而,单卡上的结果是:
| 模式 | 稳态单步 dit_forward | 相对 compile-only |
|---|---|---|
| compile | 637.8 ms | 基准 |
| compile + CUDA Graph | 638.0 ms | ≈0 |
(sdpa 后端复测同样结论:model 级 compile 573.6 ms → compile+graph 571.5 ms)
为什么?回到第1节的原理:CUDA Graph 只省 CPU 发射开销,单卡 Flux 是 compute-bound—— 看baseline trace,CPU 在 GPU 算当前 kernel 时早把下一个排好队了,发射开销被计算完全覆盖,本就不在关键路径上,反而GPU kernel一直排得满满的,此时把发射降为 0 也不影响总时间。
所以放轻松,没有收益是正常的:CUDA Graph 的收益 ∝ GPU 的 idle 时间。单卡 Flux 没有 idle,所以 0 收益——我们需要找真正有 idle 的地方。
5. 并行才是CUDA Graph的主战场?
ChituDiffusion提供了优秀的序列并行实现,可以将Ulysses和Ring Attention混合使用。把序列均匀切分,放置在多卡上,只有attention阶段需要通过Ring(环形 p2p 传 K/V)或 Ulysses(all-to-all 换头)跨卡拼完整。
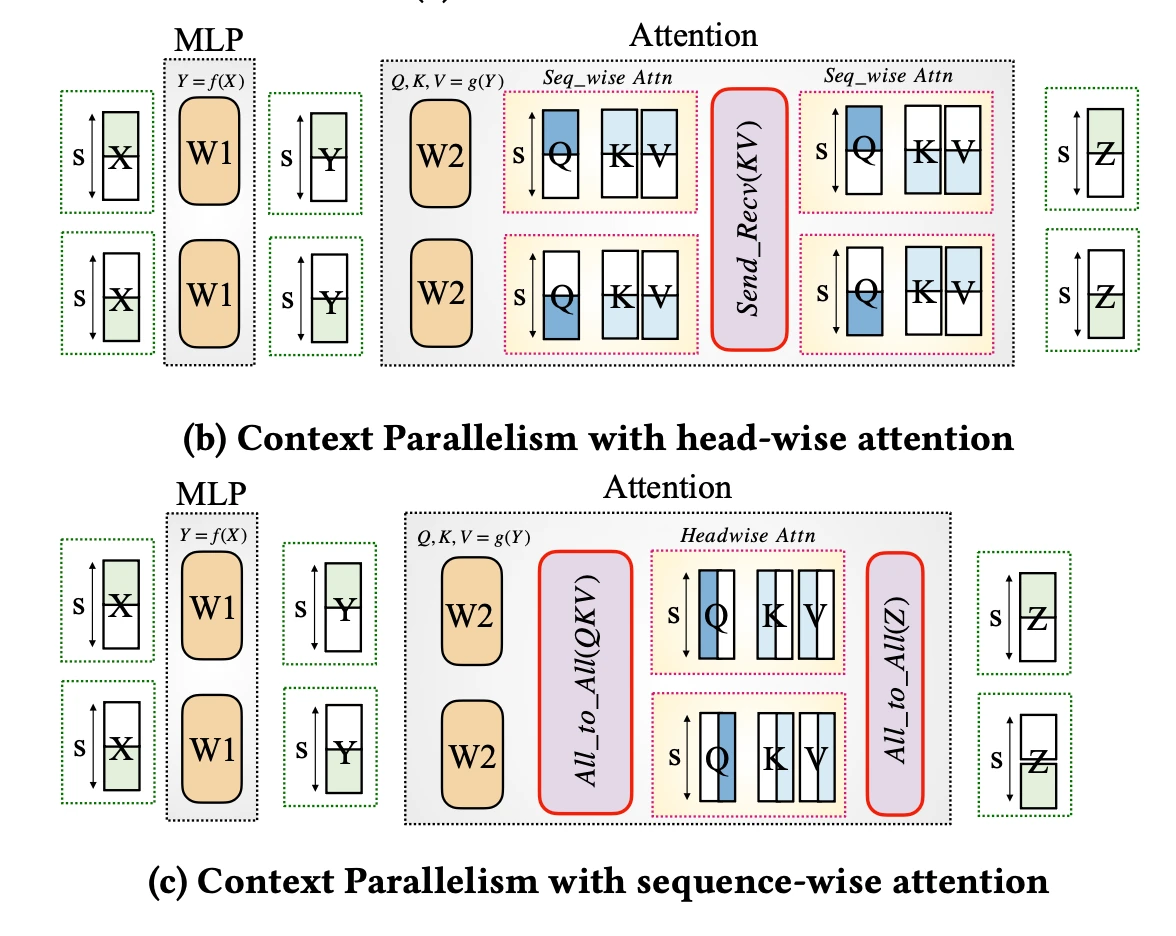
基本共识是,单机NVlink场景下,Ulysses一般比Ring Attention效果更好,ChituBench中的Parallel DiT评测结果也支持这一点。虽然 Ring Attention 能够实现计算和通信重叠,理论上比ulysses会暴露更少的通信,但多次attention kernel launch却带来了更多额外的开销。
使用 Ring Attention 开CP=8 只需:
parallel: { cfp: 1, up: 1 } # up=1 即纯 ring;cp 由卡数决定
infer: { attn_type: torch_sdpa }
但 ring 的标量加速并不线性。看它的 trace(traces/trace_ring_eager.json.gz,8 卡、每卡 576 token):
下图(rank 0)是 compute stream(7)+ NCCL stream(23)两条流:一串又长又串行的
ncclDevKernel_SendRecv(单次 ~0.45ms)占满时间轴,而每段 attention 极短(0.073ms)缩在角落
——通信远长于计算。
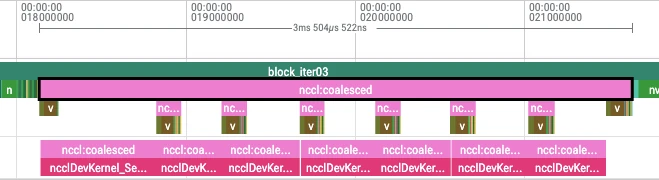
每一步注意力都要:发 NCCL p2p(ncclDevKernel_SendRecv)→ req.wait 同步 → 算一段 attention →
merge LSE,循环 cp_size 次。我们观察到,8卡时单段 attention 算得飞快,于是时间轴上
全是通信发射和等待的空隙——GPU 大量 idle 在等 CPU 把下一轮 p2p 调度上去。单 block lab 跑 6 次
forward,trace 里就有 936 个 GPU kernel、其中 42 个 ncclDevKernel_SendRecv,且每个 kernel 都对应
一次 CPU cudaLaunchKernel(共 936 次)。
更糟的是:单纯对 ring 上 torch.compile 反而更慢(8 卡 227.1ms vs origin 205.8ms)。因为
NCCL p2p 的 Work 句柄 Dynamo 抓不住,触发了 graph break,把编译区切碎。ring 这种计算+通信交织的算子,感觉 CUDA Graph 终于找到了Diffusion中的用武之地。
6. Graphed Ring Attention 带来的惊喜
6.1 思路:把整个 ring loop 录成一张图
既然 graph break 来自 NCCL p2p 与自定义 attention,那就别让 Dynamo 去抓——直接用原生 CUDA Graph capture/replay 把”整个 ring loop(p2p + attention + LSE merge)”录成一张图,每次 注意力调用回放它。一次 capture,把 cp_size 轮的全部发射/同步开销一次性抹平。
落到框架里就是一个配置开关(_cp_forward 整段被设计成 capture 安全:无 host 同步、p2p 缓冲每步清理):
infer:
diffusion:
ring_cudagraph: true # 把纯 ring loop 捕获成一张 CUDA Graph,逐步 replay
回放后的 trace(traces/trace_ring_compile_graph.json.gz)里,ring eager 那些密密麻麻的通信发射
被整体录进图、一次回放。单 block lab 跑 6 次 forward 的 CPU 发射对比最直观:
| ring eager | ring compile+graph | |
|---|---|---|
CPU cudaLaunchKernel |
936 | 0 |
CPU cudaGraphLaunch |
0 | 6(每次 forward 一次) |
| GPU kernel 总数 | 936 | 402(含 42 个 nccl SendRecv,全部录入图) |
ring eager 每次 forward 要逐个发射上百个 kernel(含 p2p,夹着等待空隙);compile+graph 把整个
block forward(compile 后的 Triton kernel + 整段 ring loop:p2p + attention + LSE merge)录成一张图,
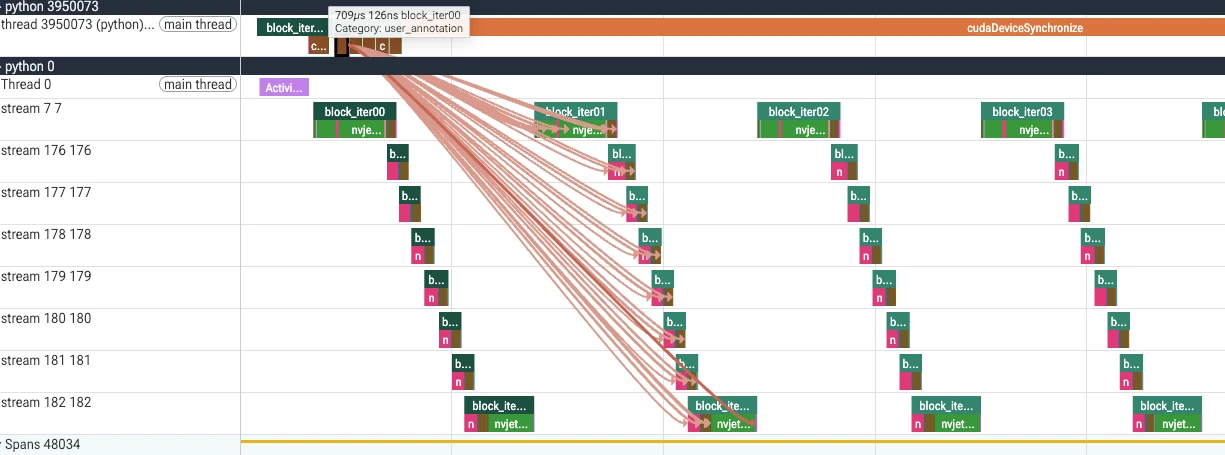
replay 时 CPU 侧只剩一次 cudaGraphLaunch——936 次逐 kernel 发射坍缩成 6 次 graph 发射,
时间轴上的通信空隙随之消失,GPU 照样跑满。看看trace,CPU一次Graph launch 对应一整个ring attention所有kernels,几十微秒就把整张图发完**,紧接着是一条又长又满的橙色 cudaDeviceSynchronize——CPU 把活全交给 GPU 后,剩下的时间什么都不干,纯阻塞等 GPU 跑完。
6.2 收益的真正来源:消除跨 rank 的 CPU 发射抖动
先看一组数(单 block lab,每次 forward):
| 指标 | ring eager | ring compile+graph |
|---|---|---|
| 墙钟 / forward | 5.25 ms | 2.10 ms |
| GPU 空闲(union) | 仅 4% | 2% |
单次 SendRecv kernel 时长 |
~0.45 ms | ~0.11 ms |
| 单次 attention(flash) | 0.073 ms | 0.073 ms |
| 通信被计算盖住 | 25% | 72% |
| GPU stream 数 | 2 | 8 |
这个结果信息量很大,首先wall clock有超过2倍的提升,但是我们期待的launch开销消除并没有发生,因为GPU本来并没有多少空闲(4%)——kernel是满的。
那性能提升发生在哪里?SendRecv的kernel从原本0.45降到了0.11,在数据量和带宽不变的情况下,kernel时间缩短了,这说明kernel注水了:有GPU空转的时间被计入了kernel内,形成了ring attention 通信bound的假象,我们再深入看看:
NCCL 的 p2p 是一次 GPU 上的握手:SendRecv kernel 启动后自旋轮询显存标志位,直到
对端配对 kernel 也上来才退出,这段自旋被算进 kernel 时长。而单机 8 卡是 8 个独立进程各驱一张卡,
per-kernel 粒度上互不同步、还抢同一颗 CPU,发射时刻必然漂移。而 NCCL 唯一的同步点在 GPU 的 rendezvous,CPU 发射侧完全不同步——慢的那个 rank 拖累所有人,每跳的
随机错位累积,把 SendRecv 撑到 0.45ms。
CUDA Graph 几乎完美破解了这个问题:整段 ring(上百 kernel + 7 次 p2p + attention + LSE merge)录成一张图,回放时
每个 rank 每步只发一次 cudaGraphLaunch,CPU 彻底退出循环,整张图由 GPU 按硬件节奏连跑。发射点从
每步几百次坍缩成一次,漂移没了累积空间——8 个 rank 锁步对齐、配对 kernel 几乎同时到达 → 自旋归零 →
SendRecv 塌回真实传输时间 0.11ms。同时 capture 把 7 个 ring hop 放到独立 stream(trace 里 8 条 stream),
让”下一跳通信”与”上一跳 attention”流水线重叠,重叠率 25%→72%,先前那些计算空泡彻底消失:
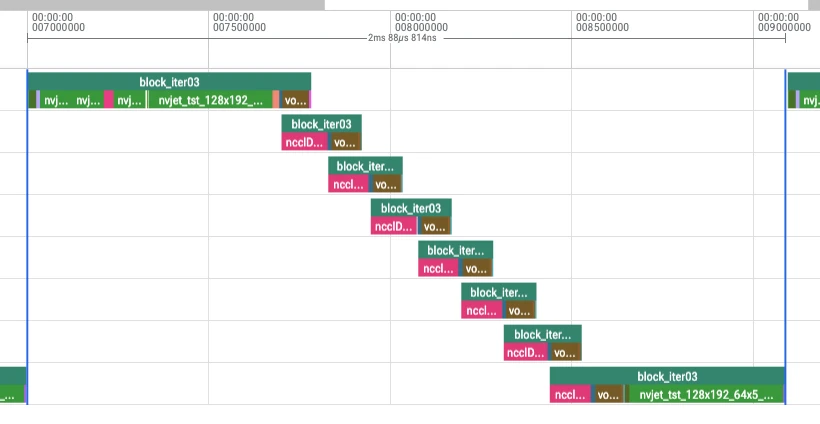
Key Insight:eager 的 SendRecv 长,不是传得慢,是在 GPU 上干等对端 rank;CUDA Graph 让 8 个 rank
锁步回放、把 CPU 踢出循环,消掉了这段跨 rank 等待。这也解释了为什么 graph 对通信密集的 ring 收益巨大,对单卡纯计算几乎为零——单卡不需要”等对端”。
6.3 性能矩阵:1 / 4 / 8 卡(flash 后端,稳态单步 ms)
| 配置 | origin | +compile | +graph | +compile+graph | ulysses(参考) |
|---|---|---|---|---|---|
| 单卡 | 762.7 | 637.8 (1.20×) | 638.0 (1.20×) | — | — |
| 4 卡 ring | 243.9 | 222.0 | 239.3 | 210.3 (3.63×) | 231.6 |
| 8 卡 ring | 205.8 | 227.1 | 166.3 | 149.8 (5.09×) | 154.8 |
- CUDA Graph 让加速重新接近线性:单层微基准里,eager 版随 cp 线性变慢(通信轮数增加),graph 版 几乎不变(只回放预录图)——所以 graph 收益随 cp_size 增长,正好补上 ring 不线性的短板。
- compile+graph 反超 Ulysses。单独 compile 会炸图,先compile做kernel融合,再整环graph减cpu开销两者叠加,能够反超当前版本的ulysses。
Plug and Play:graphed CP attention 已作为ChituDiffusion模块发布,提供接近线性的序列并行attention加速。
from chitu_diffusion.modules.attention.graphed_ring_attention import GraphedRingAttention ring_attn = GraphedRingAttention() # 默认对接 CP 进程组,每个 attention site 持一份图缓存 out = ring_attn(q, k, v) # q,k,v: (B, S_local, H, D)让 Ring Attention 再次伟大 🎉
7. FlexCache:Model-level compile/graph + 灵活计算/缓存调度
前文我们做的是block-level compile和graph,不妨大胆一点,Flux中50次迭代去噪,对应50次model-level graph launch,应该能带来更好的提升。而且,这和经典的feature cache加速方法也是契合的,像TeaCache这种比较经典的model-level cache,算与不算对应的就是graph的发射开关,近乎seamless。
更美妙的是,ChituDiffusion 内建一套缓存后端 FlexCache,统一接口下挂了多种有效的feature cache策略。
⚠️ 关于Feature Cache,我忍不住吐槽一句。
做过的人都知道这个领域有多臭多混乱——实现简陋,启发式和魔法参数横行,没有统一的评测标准,动辄4倍加速没有损失,随便一个阿猫阿狗都说自己是sota,改一行代码水一篇文章,别人辛苦拉下来跑一遍发现完全货不对板。
我做过一点这方面的研究并且深受其害,因此做了ChituDiffusion-FlexCache,就是希望统一Feature Cache的实现规格和评价标准,也给研究者们一个便捷且公正的实验环境。这个部分我后面会单写一篇文章介绍。
今天的主角是 MeanCache,它是ICLR26的工作,并不很为人知晓。但事实上,这是我读过最好的一篇 feature cache 文章,有自己的理论理解而不是纯靠瞪眼观察。因此,它实现了:
- 真正的train-free(完全不依赖魔法参数)
- 最简单的参数设置(总步数)
- 目前我所知的最好的性能(Pareto frontier)
希望大家能把它作为自己的研究baseline,而不是某些网红工作,win a real ring.
在ChituDiffusion中启用FlexCache很简单:
CHITUBENCH_FLEXCACHE_PARAMS='{"strategy":"meancache","fresh_steps":25,"use_jvp":true}'
MeanCache是model-level缓存策略:在去噪循环里判断”这一步要不要算”,决策在 model forward 之外——要算就调一次完整 forward,不算就用历史做一次有限差分 JVP 预测噪声,不进入 model 内部。这意味着:被编译/捕获的 model forward 始终是完整、形状稳定的, cache 只是决定”回放几次”。所以 step 级 cache 与 model 级 compile/graph 正交——这正是我们想要的形态:整个 DiT 一张图,外层决定 replay/skip。
我们把 compile 粒度从 block 升到 model:
infer:
diffusion:
compile_mode: reduce-overhead # 编译 + 整模型 CUDA Graph
compile_scope: model # block(默认)/ model
注意 MeanCache 的 fresh-step 表是按 50 步设计的,故本节统一 50 步。端到端 DiT 用 稳态单步 × 实际 forward 次数(排除编译噪声):
| 配置 | 单步 (ms) | forward 次数 | 端到端 DiT | 加速 | 画质 |
|---|---|---|---|---|---|
| eager | 698.8 | 50 | 34.9 s | 1.00× | 基准 |
| model compile | 573.6 | 50 | 28.7 s | 1.22× | 无损 |
| model compile+graph | 571.5 | 50 | 28.6 s | 1.22× | 无损 |
| model graph + MeanCache(25) | 572.3 | 25 | 14.3 s | 2.44× | 近无损 |
MeanCache 把 50 次 forward 砍到 25 次,单次时间不变——纯 step-skip,且与 model 级图完全正交叠加。 画质上几乎看不出差别(左:无 cache 基线;右:MeanCache,单卡 cp1,同 prompt 同 seed):

8. 全家桶:端到端 9.74×
最后把四项优化逐层叠起来,最终能够达到什么效果呢?
| 阶段 | 配置 | dit_forward(50 步) | 单步 | 累计加速 | 是否无损 |
|---|---|---|---|---|---|
| ① | 单卡 eager(origin) | 37.9 s | 762.7 ms | 1.00× | — |
| ② | + torch.compile | 31.7 s | 637.8 ms | 1.20× | ✅ 感知无损(见 3.3) |
| ③ | + ring graph(cp=8) | 7.49 s | 149.8 ms | 5.06× | ✅ 无损(bit-exact) |
| ④ | + FlexCache(MeanCache 25) | 3.89 s | 26 次 forward | 9.74× | ≈ 近无损 |
每一层的来源都对得上:①② 是单卡 flash 实测(与 6.3 矩阵的 762.7 / 637.8 ms 一致);③ 取 6.3 的 8 卡 compile+graph 单步 149.8 ms × 50;④ MeanCache 把 50 次 forward 砍到 26 次(其余整步跳过), 7.49 s × 26/50 ≈ 3.89 s,正是 showcase 右图的速度。
画质代价(全家桶 vs 单卡 eager,同 prompt 同 seed,3 张海报均值):
| 指标 | 全家桶(cp8+graph+MeanCache25) |
|---|---|
| PSNR | 26.1 dB |
| SSIM | 0.87 |
| LPIPS ↓ | 0.073 |
| HPSv3(绝对分) | 12.96(基线 12.93) |
像素级有可测偏差——但这来自 cp8 的数值路径(ring 分片累加)+ step 缓存 的叠加,而非”质量变差”: HPSv3 人类偏好分与基线持平甚至略高,开篇 showcase 三张图肉眼也分不出来。
ChituBench 实测 cp=8 与 cp=1 出图一致:

四层里 ②③(compile + ring graph)感知/逐位无损,第四层(MeanCache)近无损。从单卡朴素的 37.9 s 压到 8 卡全家桶的 3.89 s,端到端 9.74×,而画质肉眼无差。
9. 结语
| 策略 | 优化层面 | 何时有效 | 本文收益 |
|---|---|---|---|
| torch.compile | GPU 计算(融合 kernel) | 有可融合的访存尾巴 | 单卡 1.20× 无损 |
| CUDA Graph | CPU 发射/调度 | launch-bound(GPU 有 idle) | 单卡 0;8 卡 ring 关键 |
| compile + ring graph | 二者叠加 | 并行通信密集 | 8 卡 5.09×,反超 Ulysses |
| + FlexCache(step) | 跳过整步 | 与 model 级图正交 | 端到端 9.74× |
AI给我总结了三个要点:
- 先 profile,再优化。 “小模型一定 launch-bound、CUDA Graph 一上就起飞”是常见误判;到底有没有 idle、有没有可融合的碎kernel,必须先做性能分析确认(Wan vs Flux、单卡 vs ring 就是正反例)。
- 按 regime 选武器、按粒度做编译。 compile 吃访存尾巴、graph 吃发射空隙;单卡用 block 粒度, 要叠 step 级 cache 就升到 model 粒度——一张完整图,外层决定 replay/skip,将控制面和数据面分开。
- 无损与有损分轴叠加。 compile/ring-graph 是纯加速,FlexCache 是可控的质量-速度权衡;二者正交, 可以一路叠到端到端 9.74×。
最后也借这个实验正式介绍一下 ChituDiffusion:它想做的事情很简单,把 Diffusion 推理里的模型、注意力后端、并行方式、缓存策略和评测流程,都放进同一套可复现、可替换、可组合的工程框架里。本文从单卡 compile,到 8 卡 ring graph,再到 FlexCache 的 step 级调度,基本就是这套设计初衷的一次完整演示。
目前它已经支持统一配置、可插拔 attention 后端、原生上下文并行、FlexCache 缓存接口和 ChituBench 基准框架。代码还在快速演进,我们也还没有足够的人力及时适配所有新模型;如果你也关心 Diffusion 推理加速、并行运行时或 feature cache 的可靠评测,欢迎一起试用、提 issue、贡献模型和后端。
GitHub:https://github.com/thu-pacman/ChituDiffusion
附录 A:可复现环境与归档
- 硬件:NVIDIA H20(Hopper),单机 1 / 4 / 8 卡,经 slurm 派发
- 软件:torch 2.9.1+cu130,ChituDiffusion
- 模型:Flux.1-dev(1024×1024,flowmatch-euler);对照 Wan2.1-T2V-1.3B
- 多卡需
export NCCL_GRAPH_MIXING_SUPPORT=1
完整可复现资源包已作为 GitHub Release asset 单独发布:
https://github.com/thu-pacman/ChituDiffusion/releases/tag/zhihu-cudagraph-compile-repro-20260621
下载后解压即可得到 zhihu_cudagraph_compile/ 归档目录:
| 子目录 | 内容 |
|---|---|
article.md |
本文 |
results.md |
完整性能矩阵与复现命令 |
configs/ |
单卡 / ring / wan 基线的自包含配置 |
code/ |
block_trace_lab.py(单 block + ring,生成 4 张 trace)、ring_attn_lab.py 等实验脚本 |
traces/ |
trace_{single_eager,single_compile,ring_eager,ring_compile_graph}.json.gz(perfetto 打开,按 block_iterNN 定位) |
images/ |
画质对比图 + 5 张 trace 截图(均已就绪) |
data/ |
原始日志与 prompt |
worklogs/ |
Wan 对照实验与补充记录 |